TiDB 源端增量同步架构优化实践
背景
TiDB 源端同步的初期实现主要借鉴了 Flink CDC 的方案。这种方式在处理小规模同步任务时运行稳定,但在面向 大规模 Region 并发同步 时,逐渐暴露出多个问题,例如事件乱序、处理瓶颈和错误恢复机制薄弱等,难以支撑长时间高负载运行。
为了解决这些问题,后续对 TiCDC(TiDB 官方提供的变更数据捕获组件,现已更名为 TiFlow)进行了深入研究。分析其在 Region 拉取、变更排序、下游写入 等核心模块中的机制,并结合业务场景和系统约束,使用 Java 语言重构实现了同步系统的底层核心逻辑。
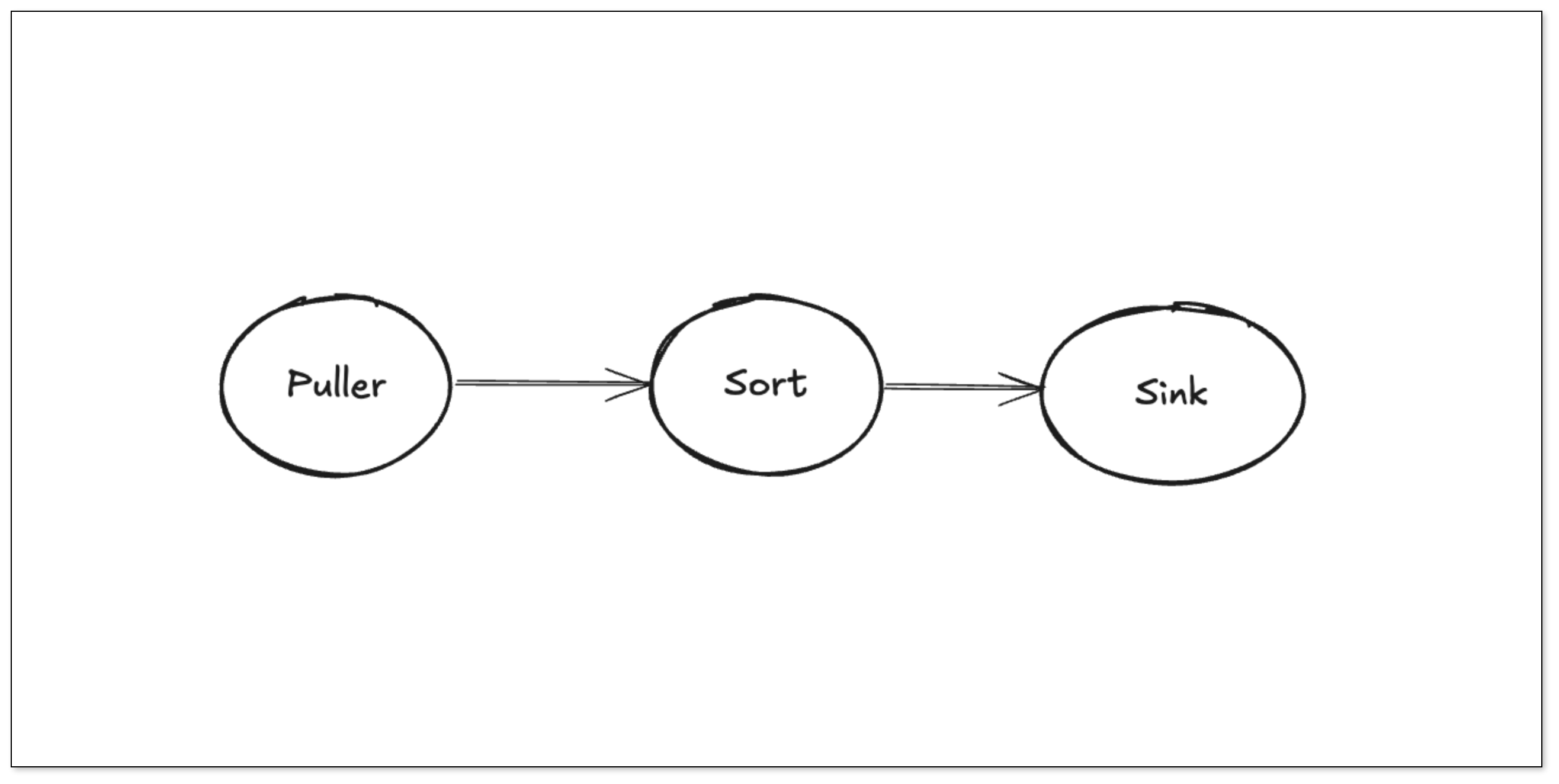
整个增量同步系统被拆解为三个关键模块:
- Puller:基于 Region 粒度建立与 TiKV 的并发拉取通道,接收变更事件
- Sort:采用嵌入式 RocksDB 对变更事件进行持久化缓存和事务内排序
- Sink:按表维度并发读取排序结果,将数据投递给下游消费方(如 PostgreSQL、ES 等)
新架构在 Java 生态中具备良好的可维护性和可扩展性,具备异步流式处理、内存控制、分布式调度等能力,有效提升了在 高并发、大事务、高变更密度 场景 下的稳定性与吞吐能力。
了解 TiDB
TiDB 基本组件
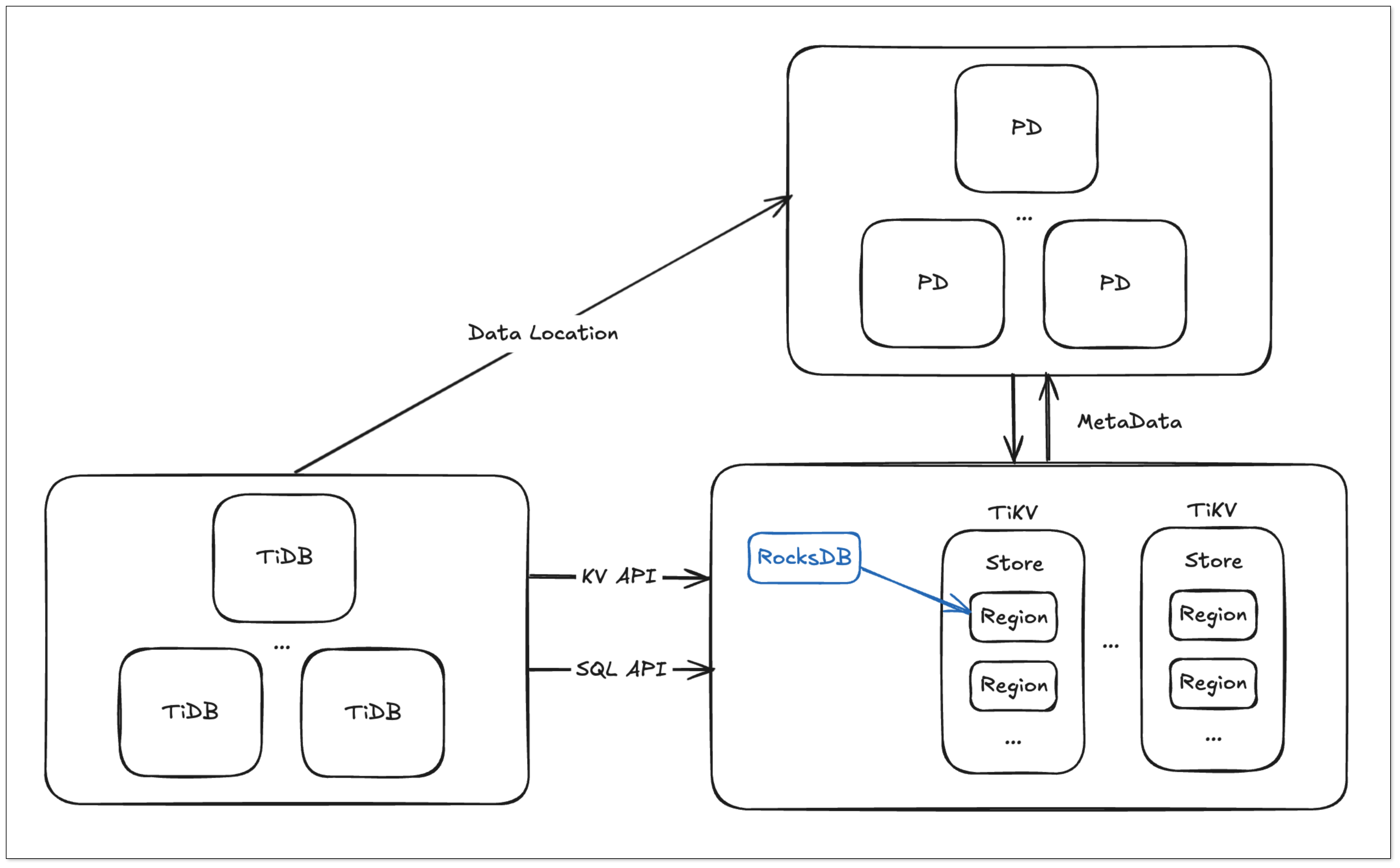
- PD Server 是集群的管理模块,主要负责存储元信息、调度 TiKV 集群并分配全局唯一的事务 ID。
- TiDB Server 处理 SQL 请求,通过 PD 获取 TiKV 的数据地址,与 TiKV 交互获取数据。TiDB 无状态,可无限水平扩展,并通过负载均衡提供统一接入。
- TiKV Server 负责存储数据,使用 Raft 协议保证数据一致性和容灾,数据的存储和调度以 Region 为单位进行,PD 负责调度和负载均衡。
关系模型映射到 KV 模型
关系模型
假设我们有一个如下定义的表:
CREATE TABLE User {
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
Key idxAge (age)
};
在关系模型中,存储的数据通常分为以下三部分:
- 表的元信息
- 表中的行数据(Row)
- 索引数据(包括主键和二级索引)
在 TiDB 中,系统为每个表分配一个唯一的 TableID,每个索引分配一个 IndexID,每行数据分配一个 RowID(如果表的主键为整数类型,则直接使用主键值作为 RowID)。这些 ID 类型均为 int64,其中 TableID 在集群内唯一,IndexID 和 RowID 在表内唯一。
行数据编码规则
每行数据按照如下规则编码为一个 Key-Value 对:
- Key: tablePrefix{tableID}_recordPrefixSep{rowID}
- Value: [col1, col2, col3, col4]
其中,tablePrefix 和 recordPrefixSep 是用于在 KV 空间中区分其他数据的固定字符串常量。
索引数据编码规则
索引数据按照以下规则编码为 Key-Value 对:
- Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
- Value: rowID
索引数据需要考虑唯一索引(Unique Index)和非唯一索引(Non-Unique Index)两种情况:
- 唯一索引(Unique Index)可以按照上述规则直接编码。
- 非唯一索引(Non-Unique Index)的编码需要调整,因为相同的 indexedColumnsValue 可能出现在多行数据中,这样无法构造唯一的 Key。因此,非唯一索引的编码规则为:
- Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID
- Value: null
常量定义
var(
tablePrefix = []byte{'t'}
recordPrefixSep = []byte("_r")
indexPrefixSep = []byte("_i")
)
无论是行数据(Row)还是索引数据(Index),同一个表的所有行数据具有相同的前缀,同一个索引的数据也具有相同的前缀。
这样,具有相同前缀的数据在 TiKV 的 Key 空间内将排列在一起。
举个例子
假设表中有以下 3 行数据:
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
假设该表的 TableID 为 10,主键为 ID,则每行数据的 Key-Value 对如下:
- t10_r1 → ["TiDB", "SQL Layer", 10]
- t10_r2 → ["TiKV", "KV Engine", 20]
- t10_r3 → ["PD", "Manager", 30]
此外,该表还有一个索引(idxAge),假设其 IndexID 为 1,则索引数据的 Key-Value 对为:
- t10_i1_10_1 → null
- t10_i1_20_2 → null
- t10_i1_30_3 → null
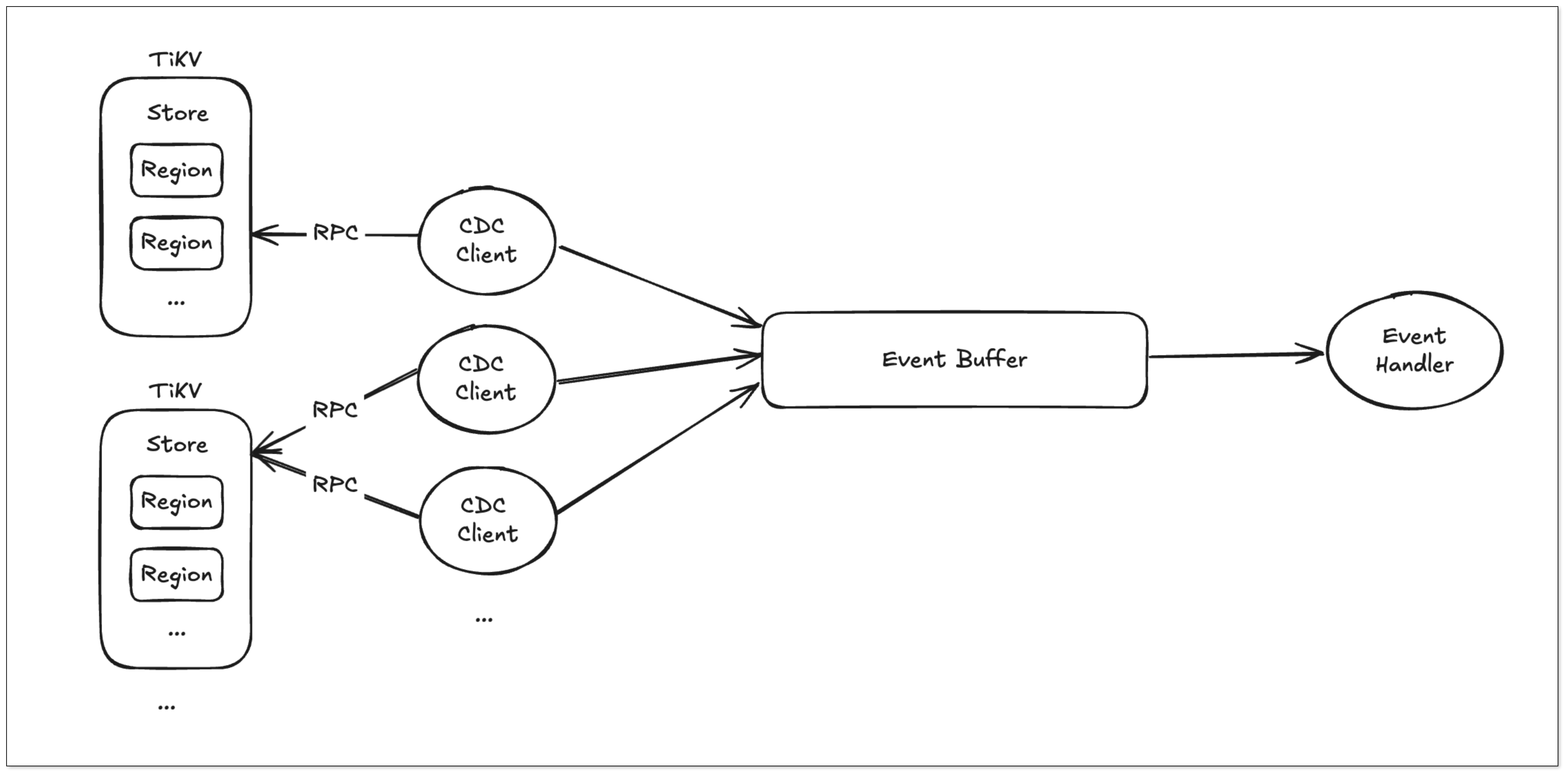
TiDB CDC 原理
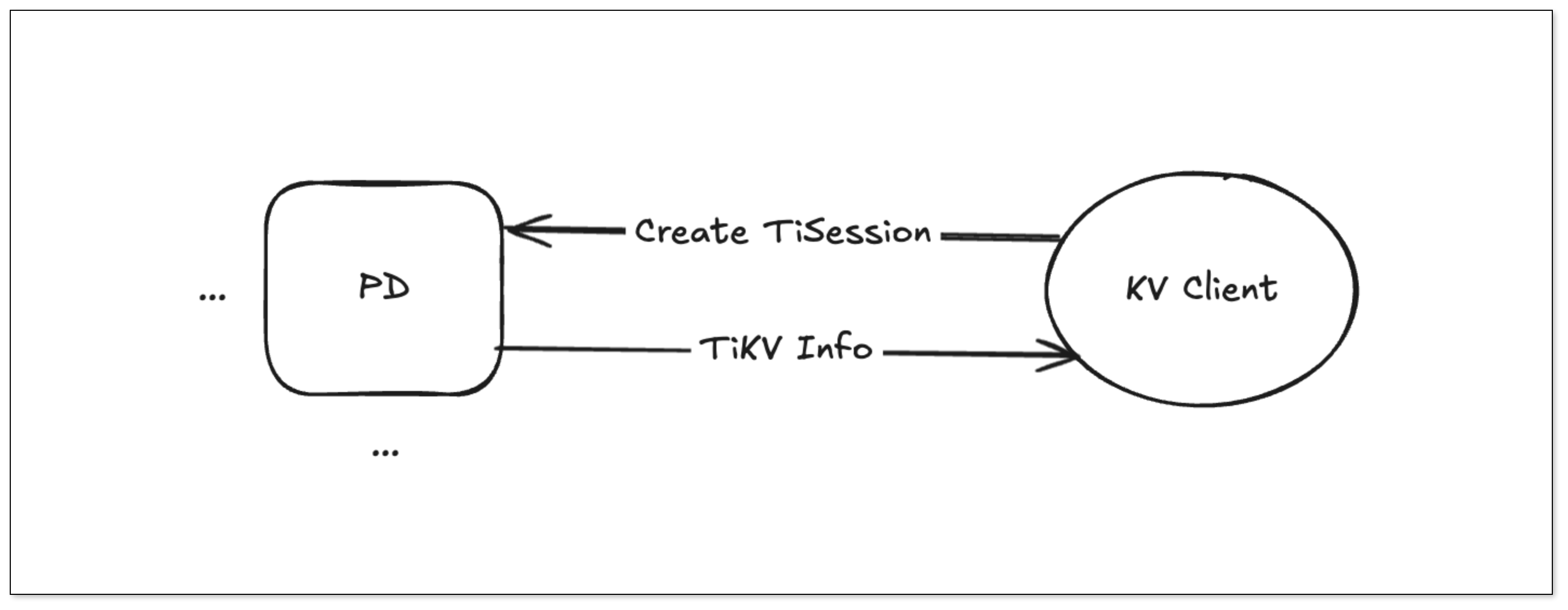
KVClient 和 PD 建立连接后创建一个 TiSession,其中包含了所有 TiKV 节点信息。
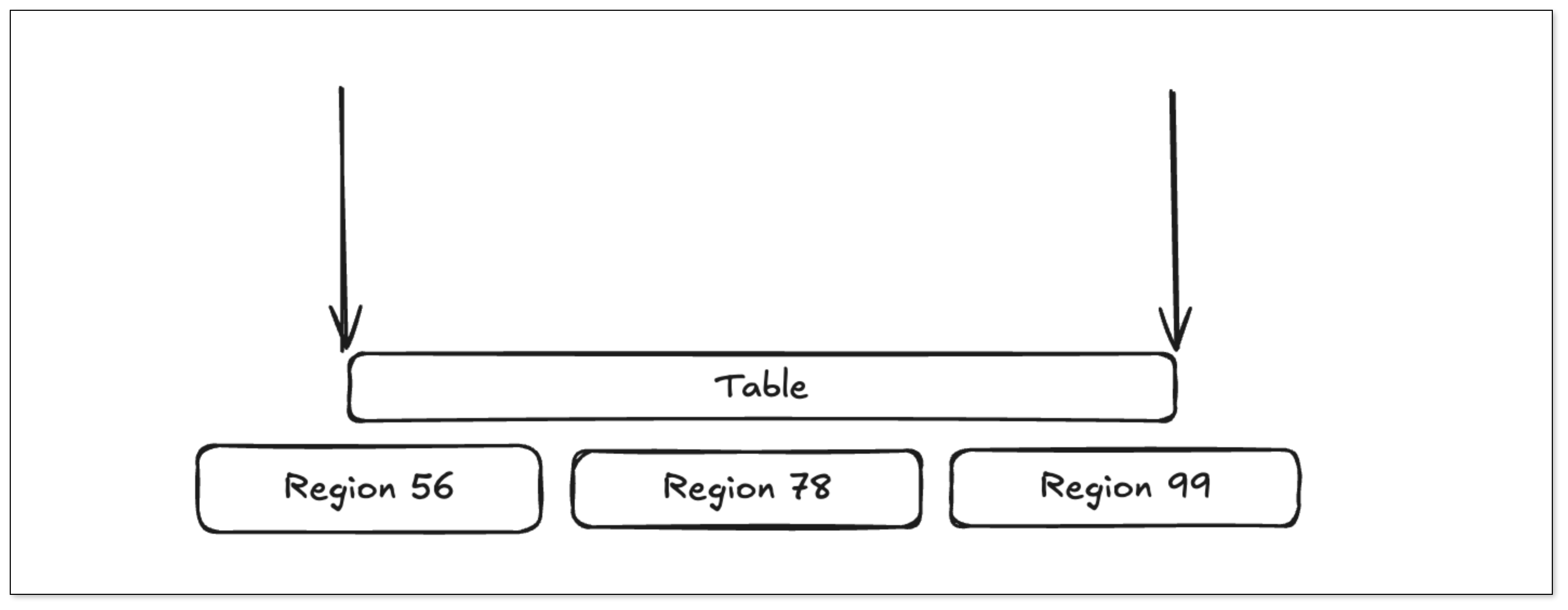
获取 Table 的 TableID 计算出 Table 的 KV 范围,从 TiSession 中获取这个范围的 Region 信息。
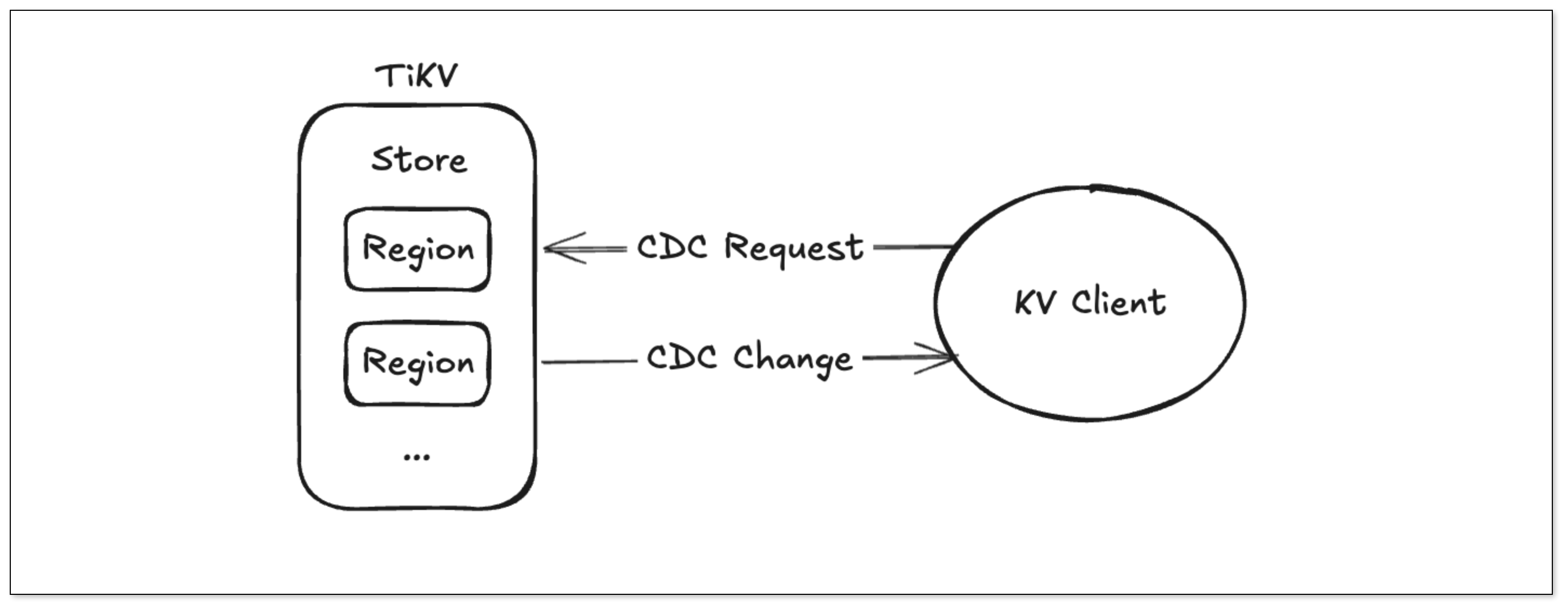
建立 Regin 下面的 Store 的 grpc 通信,发送获取 CDC 变更请求,最后处理请求。
Flink CDC 存在的问题
- 大量 Region 的同步报错。
- 单线程事件处理性能较弱。
- CDC 数据没有进行排序。
重构优化
最初采用 Flink CDC 的实现方式难以满足实际需求,因此后续转向深入阅读 TiCDC(TiDB 官方提供的变更订阅工具,现已更名为 TiFlow)的源码,通过学习其在 CDC 数据捕获与处理方面的机制,最终确立了以 Puller、Sort、Sink 为核心的同步架构,并由此展开具体的编码实现。
- Puller:拉去 CDC 变更数据,并行处理。
- Sort:以 RocksDB 为 KV 存储结构,自带排序。
- Sink:并行从 RocksDB 中读取数据。

Puller 模块

Puller 发送了什么请求
ChangeDataRequest 结构定义了向 TiKV 发送请求的所有信息:
- CheckpointTs 表示从哪一个时间点开始同步数据。
- RegionId 表示向 TiKV 的哪一个 region 请求变更事件。
- ExtraOp 定义了一些请求的扩展性属性,现在使用的 old value 输出标志就是附加在这个字段上的。
ChangeDataRequest{
Header: header,
RegionId: regionID,
RequestId: requestID,
RegionEpoch: regionEpoch,
CheckpointTs: sri.resolvedTs,
StartKey: sri.span.Start,
EndKey: sri.span.End,
ExtraOp: extraOp,
FilterLoop: s.client.filterLoop,
}
Puller 创建一个 KV-Client 并向 TiKV 发送 ChangeDataRequest 请求,从而从 TiKV 接收变更数据。
- TiKV 按照 Region 为单位,发送数据变更事件和 Resolved Ts 事件。
- Resolved Ts 事件表明该 Region 中所有 Commit Ts 小于该 Resolved Ts 的事件都已被发送完成。
- Puller 从 KV-Client 接收数据,将其写入 Sorter 中,并持续推进表级别的 Resolved Ts。
Region Worker 事件处理
Region worker 负责处理与 TiKV store 推送的所有 Region 的数据操作,推送事件时会根据 Region ID 对 Worker 的数量进行取模,这样确保同一个 Region 的数据是顺序消费的。
TiKV 事件处理过程
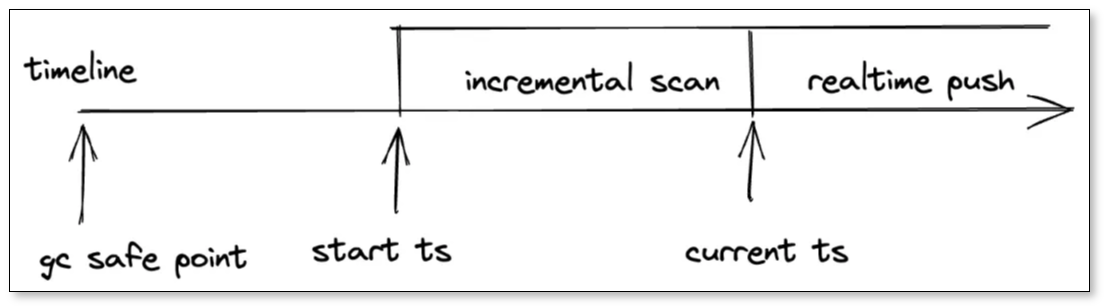
- 增量扫阶段:这个阶段获取 Region 的 Snapshot,读取某段时间范围内的数据更改,分为三类事件:
- Prewrite:上锁记录。
- Committed:提交记录。
- Initialized:表示增量扫结束,后续发送 Resolved Ts 事件。
- 实时推流阶段:推送上游写入的实时数据;TiKV 将这两个阶段的 KV 数据通过 gRPC 进行传输。
Region Worker 处理事件具体流程
- Committed:已提交事务,直接输出到 Sort 模块。
- Prewrite:缓存到内存中,等待 Commit 事件。
- Commit:匹配到对应的 Prewrite 事件,组成完整事务后输出。
- Rollback:清理缓存的 Prewrite 事件。
- Initialized:标记 Region 初始化完成,并处理 cachedCommit 事件。
- ResolvedTs:将 Resolved Ts 发送到 Resolved Ts Queue。
推进表级别的 Resolved Ts
Region Worker 输出的 Resolved Ts 是 Region 级别的,但下游需要的是表级别的 Resolved Ts,这里需要一个模块对多个范围中的最小 Ts 进行计算。
Frontier 模块的主要功能是帮助计算整个 Puller 级别的最小 resolved ts,并对外输出。
- forward 方法:接收某个 Region 的 Resolved Ts 及其 KV 范围,更新 Frontier 内部的数据结构。
- frontier 方法:返回 Puller 级别的最小 Resolved Ts。
Puller 的处理流程
- KV 事件处理:如果 Region Worker 输出的事件是 KV 事件,Puller 直接发送到 Sort 模块中。
- Resolved ts 事件处理:如果事件是 Resolved Ts,Puller 调用 Frontier 的 forward 方法,将 Region 的 Resolved Ts 和其 KV 范围传入,Frontier 内部会维护一个最小堆,通过更新最小堆中的值来重新计算整个范围内的最小 Resolved Ts。Puller 最终会调用 Frontier 方法,得到当前范围内的最小 Resolved Ts。
举个例子
假设一个 Puller 同步的表由 6 个 Region 组成,它们当前的 Resolved Ts 分别为(最小为 2):
6,3,2,5,4,7如果后续收到 Region 的 Resolved Ts 事件,向前更新为 4,则更新后的 Resolved Ts 值变为:
6,3,4,5,4,7此时,Puller 会通过 frontier 方法计算出所有 Region 的最小 Resolved Ts 是 3。于是 Puller 会输出一个 Resolved Ts 值为 3 的事件,通知下游这个时间戳之前的所有 KV 数据都可以处理了。
错误处理
Region Worker 在处理事件的时候会发生一些错误,同时也可能会收到一些由 TiKV 发过来的错误,比如说 region not found、not leader 等等。
会根据错误的类型来判断是否需要重新调度 Region 请求。一些错误是不预期或者不可重试的,比如 DuplicateRequest,Compatibility,ClusterIdMismatch,遇到这类错误时 Puller 就直接报错,而其他可重试的错误则会调用 scheduleRangeRequest 或 scheduleRegionRequest 来重新调度 Region 所覆盖的范围,再一次完整的走过请求的流程。
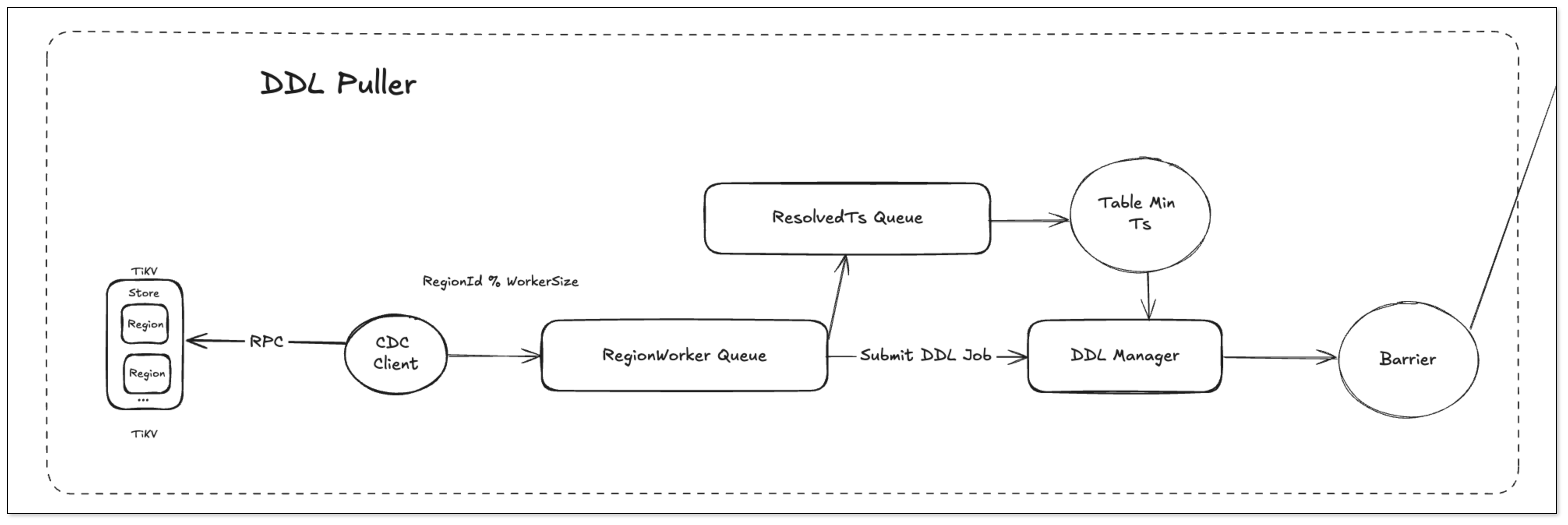
DDL 事件捕获
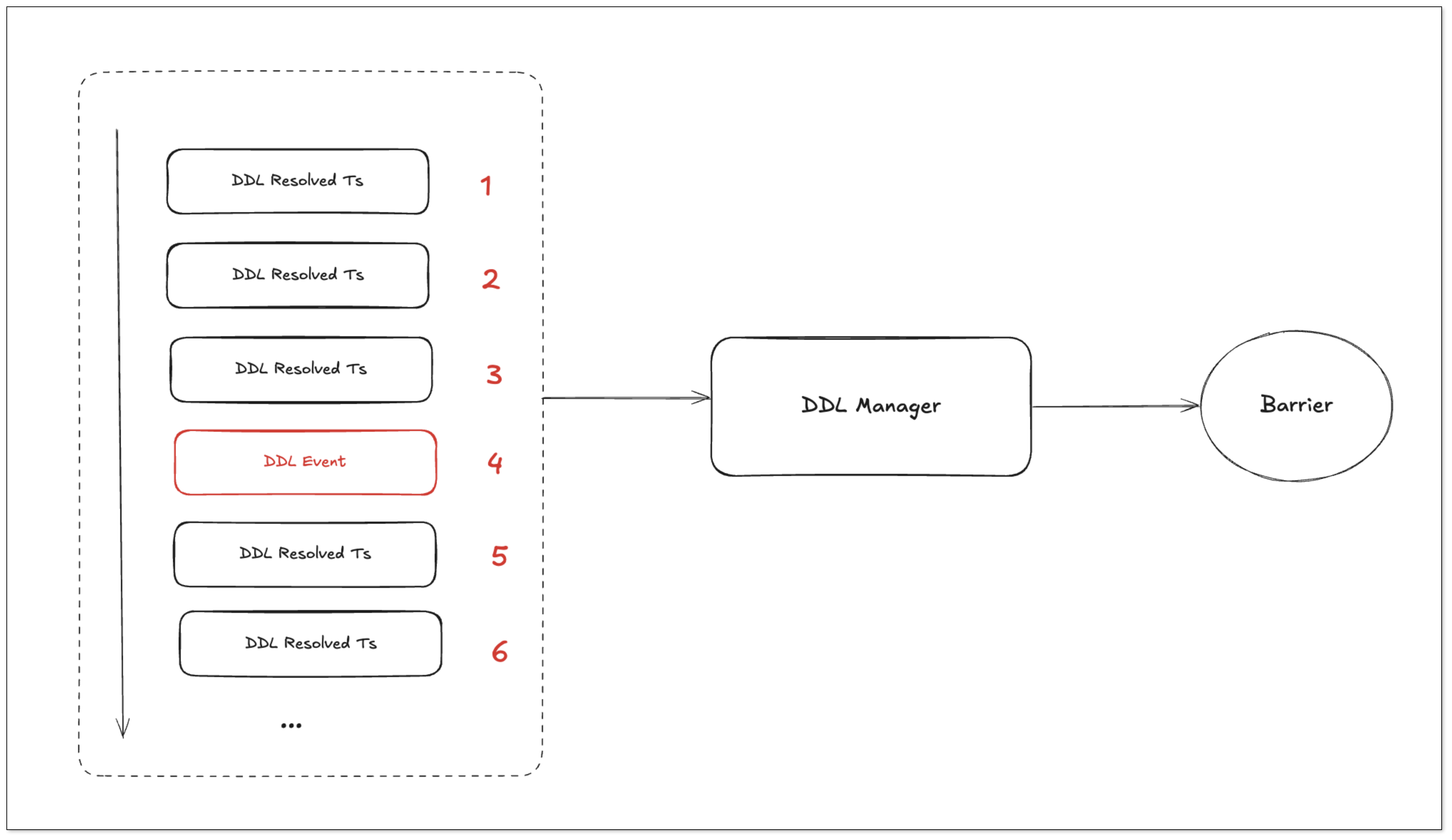
DDL 在 TIDB 中为一个特殊表,表的 ID 为 MaxInt48 - 1,因此底层捕获数据的逻辑与 DML 相同,都是向 TiKV 中请求事件变更请求,但和 DML 处理不同的是,这里涉及到下游 Barrier Ts 的计算。
DDL 计算 Barrier Ts 是通过 DDL Manager 来定时计算的:
- DDL Puller 更新 Resolved Ts:接收 KV 事件并持续更新 Resolved Ts。
- DDL Manager 定时计算 Barrier Ts:
- 当系统没有 DDL 事件时,DDL Manager 以 DDL Puller 的 Resolved Ts 作为 Barrier Ts。
- 下游 Sink 在消费事件时,不会超过当前的 Barrier Ts。
- DDL Manager 接收到 DDL 事件:
- 将当前 DDL 事件的 StartTs 设置为 Barrier Ts。
- 停止更新 Barrier Ts。
- 下游 Sink 的 CheckPointTs 与 Barrier Ts 相等时,才会执行 DDL。

Sort 模块
为什么要 Sort
作为磁盘缓冲
Sorter 的上游是 Puller 实例,后者创建 KV-Client 从 TiKV 获取每个 Region 的行变更,经过一系列处理后交给下游的 Sink。
显然,Sink 的吞吐上限可能是低于 KV-Client 的输出的,特别是在需要同步大存量数据到下游的情况下。
排序
由于 KV-Client 以 Region 为单位从上游获取行变更事件,多个 Region 之间的事件显然是乱序的。
增量扫的数据流和实时数据流相互独立,因此在一个 Region 内部同一行的多次变更,最终推送的顺序也可能是乱的。因此,Sorter 需要担负起这个排序的任务。
还原事物
在 Sorter 的上游,行变更是以行为单位进行收集的;在下游 Sink 模块中,行变更是以事务为顺序输出的。
也就是需要在存储时,同一个表内的行变更以 CommitTs 和 StartTs 为前缀排序,这样属于同一个事务的所有行变更就被聚合在一起了,这样就还原了上游事务的顺序。
Sort 实现
TiDB 如何将 Row 映射为 Key / Value 对
- {TableID} | {RecordID} -> Value { columns }
Sort 中的 Key 编码格式
- TableId | CommitTs | StartTs | {TableID} | {RecordID} | OperationType;
- TableId 作为最高前缀,方便以表单位获取数据;
- CommitTs 决定了事物的可见性;
- StartTs 唯一标识一个事物
在 TiDB 中,表 ID 和行记录 ID 会编码为 Key 的前缀,所有的列会编码到一个大的 Value,于是关系数据库表的数据便可以此形式存储到 Key-Value 存储引擎中。
Sort 会对 TableID 和 RecordID 的 Key 再次编码,使得事件以 TableId、CommitTs、StartTs 等为前缀来存储。
编码之后,便可以调用 API 将事件写入 RocksDB 实例中,其中包含了一些攒批写入。
Sink 模块
Sink 模块主要是读取 RocksDB 中的数据,每个 Table 都会初始化一个 Sink Worker。
读取时会以 (TableID + checkPointTs, TableID + MaxTs] 这个范围进行读取,当然读取上界会有限制:
- 每个表都会有它自己的最小 Resolved Ts。
- DDL Puller 同时也有一个 Barrer Ts。
读取上界就是 最小 Resolved Ts 和 Barrer Ts 取最小值进行读取,这样保证写入下游的数据和 DDL 是顺序的。
总结
这套增量同步系统是在参考 Flink CDC 和 TiCDC 的基础上,结合实际业务需求重新设计的。通过 Puller、Sort、Sink 三个模块的拆分,把数据拉取、排序、写入下游的流程做了更细致的控制。
在架构上利用了 TiDB 的 KV 存储模型,同时用 RocksDB 做了事务级别的排序和持久化,整体思路简单但效果不错。最终,这套方案在应对大事务、高并发、长时间运行等场景下,稳定性和吞吐都有明显提升,也为后续支持更多功能打下了基础。